



作为科研人或者写作者,最令人煎熬的时刻之一,莫过于在提交稿件后,那漫长而未知的等待。每天一遍又一遍地登录期刊投稿系统,刷新页面,只为看到那个小小的状态更新,这不仅浪费时间,更是一种精神内耗。如果能有一个私人助理,24x7小时不知疲倦地帮我们紧盯状态,一旦有任何风吹草动,立刻通过微信通知我们,那该多好?今天,我们就来亲手打造这样一个智能助理!本教程将带你从零开始,使用 Python、强大的浏览器自动化工具 Playwright,以及微信官方的测试公众号接口,构建一个全自动的期刊投稿状态监控与推送机器人。(不同期刊的投稿系统不同,因此playwright模拟登录的过程会有所不同,在此仅以Elsevier的投稿系统为例)
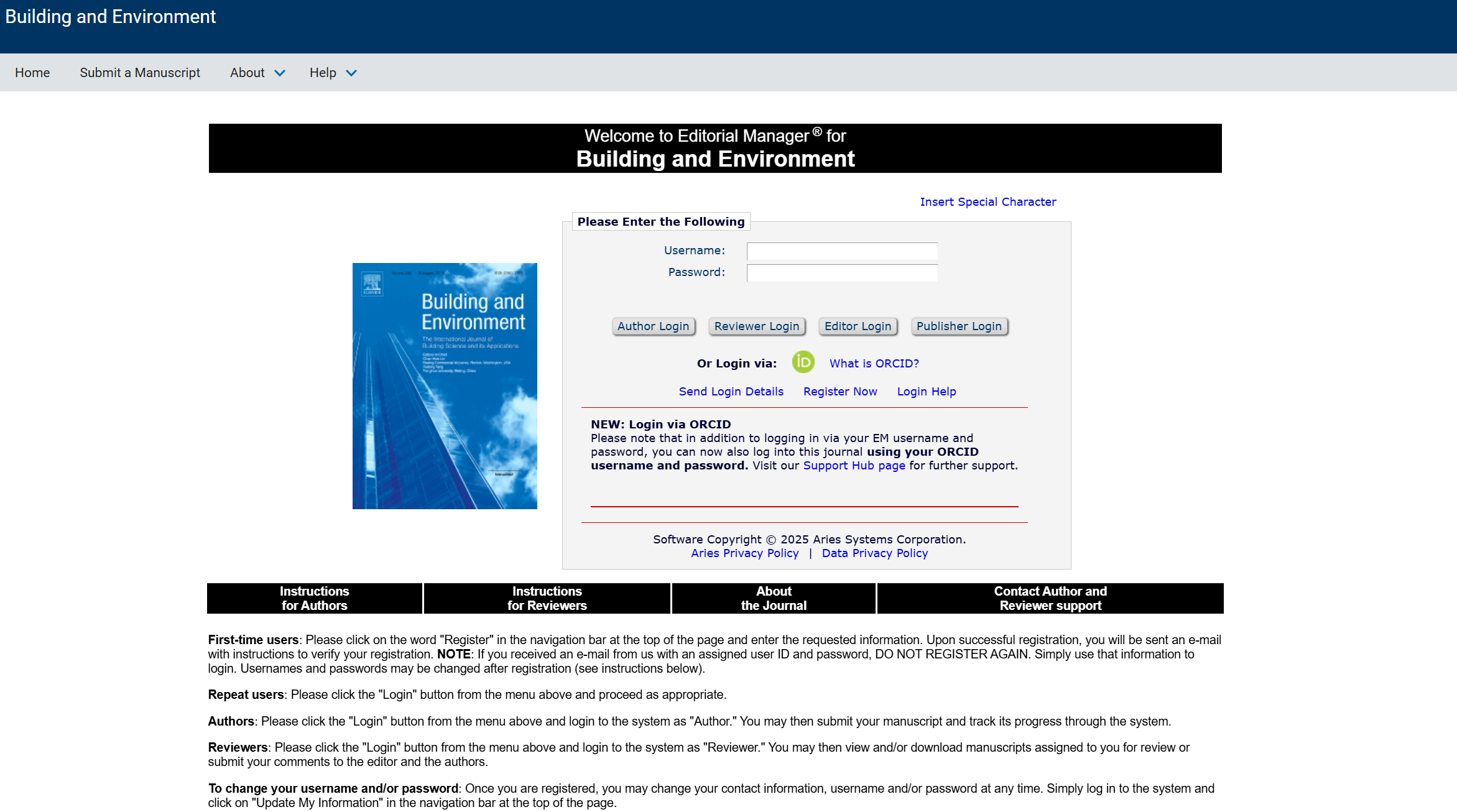
最终效果: 当你的投稿状态从 "With Editor" 变成 "Under Review" 时,你的手机会立刻收到一条这样的微信消息:
您的期刊投稿状态有新的变化!
检查时间: 2025年07月24日 14:00 变更前状态: With Editor 变更后状态: Under Review
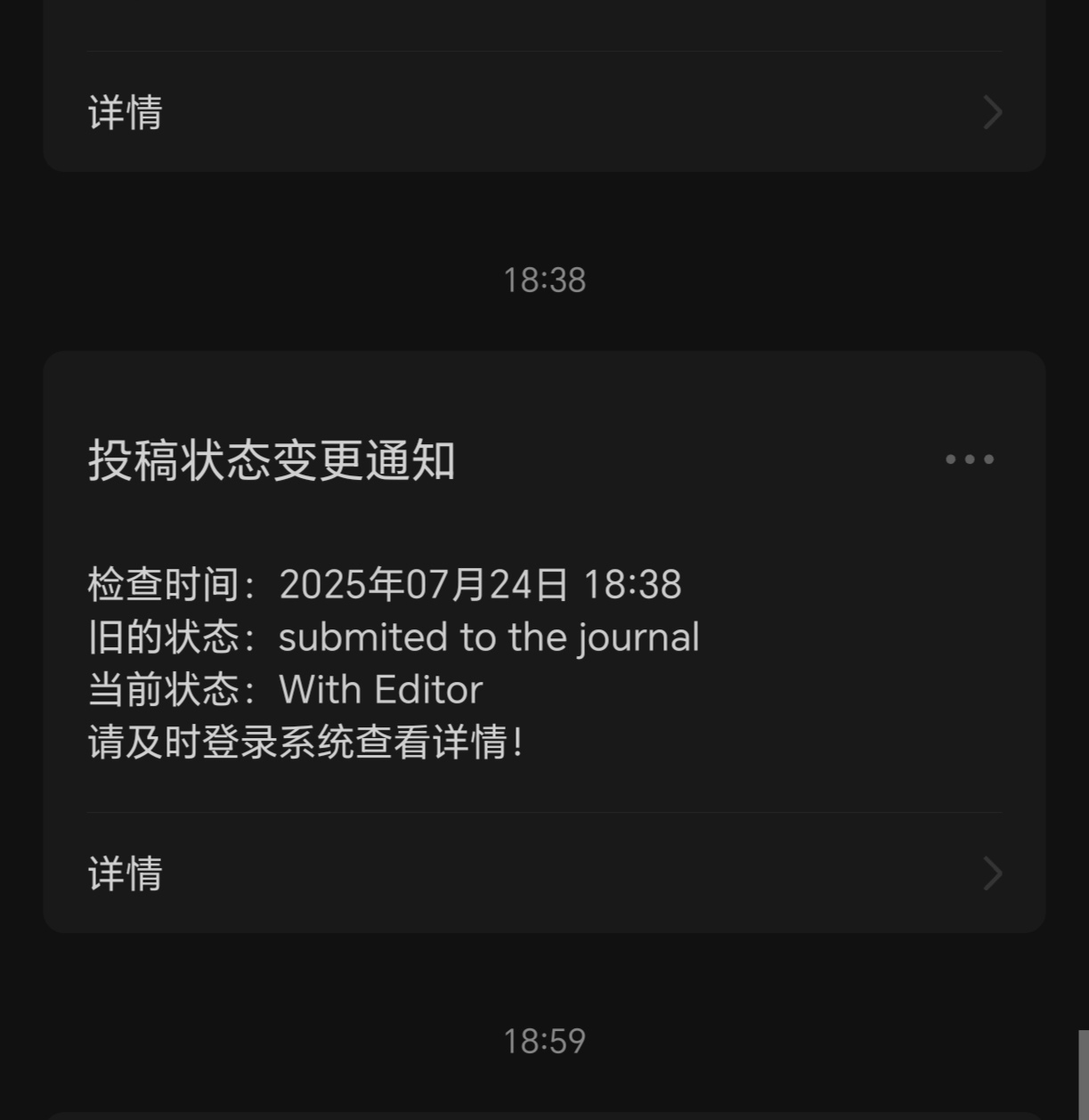
从此,告别焦虑,解放双手,让时间和精力回归到更重要的科研与创作中去!
Part 1: 项目蓝图与技术选型
我们的机器人工作流程非常清晰,就像一位尽职的秘书:
- 定时唤醒:机器人每隔一段时间(例如45分钟)自动“醒来”开始工作。
- 模拟登录:像真人一样,打开浏览器,输入账号密码,登录到期刊的投稿系统网站。为了高效,它会记住登录状态(Cookies),下次能跳过登录直接进入。
- 抓取信息:在网页上精准找到稿件状态那一栏,读取当前的最新状态文本。
- 比对分析:将新抓取到的状态与上次记录的状态进行比较。
- 决策与行动:
- 如果状态没有变化,就默默记下检查时间,然后继续“睡觉”。
- 如果状态发生了变化,立刻整理信息,通过微信接口给你发送一条通知。
- 智能容错:如果中间遇到网络问题或网页加载慢,它会尝试几次,而不是轻易放弃。
为了实现这个蓝图,我们选用以下几位“得力干将”:
- Python: 我们项目的核心语言,胶水般的存在。
- Playwright: 微软出品的新一代浏览器自动化工具,能够精准地模拟人类在浏览器上的所有操作,并且对处理复杂的网页(比如包含
iframe的网站)有奇效。 - Requests: 用于和微信服务器API打交道,发送我们的通知消息。
- Schedule: 一个非常优雅的Python定时任务库,让我们的脚本可以按照预设的时间表自动运行。
- 微信测试公众号: 微信官方提供给开发者的免费“试验田”,可以实现完整的消息推送功能,完美满足我们的需求。
Part 2: 准备工作 - 配置你的“武器库”
在编写代码之前,我们需要先准备好所有必需的“弹药”。
1. 安装Python库
打开你的终端或命令行,安装我们项目需要的所有第三方库:
pip install playwright schedule python-dotenv requests
安装完 playwright 库后,还需要下载它所控制的浏览器核心文件,非常简单,只需一行命令:
playwright install
2. 获取微信测试号信息
这是我们能收到通知的关键。请访问 微信公众平台接口测试帐号 1 申请页面,用你的微信扫码登录。
登录后,你将看到一个信息面板,请记下以下几个关键信息:
appIDappsecret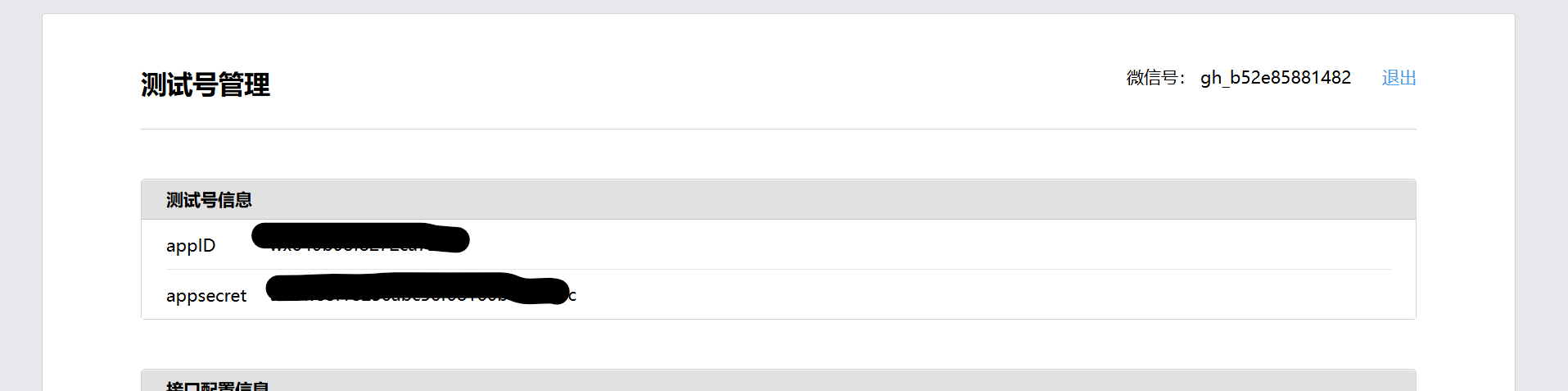
向下滚动页面,找到“测试号二维码”,让接收通知的微信(可以是你自己)扫描这个二维码并关注。关注后,该用户的微信号(一串以o开头的字符)会出现在下方的“用户列表”中,这就是我们的:
openId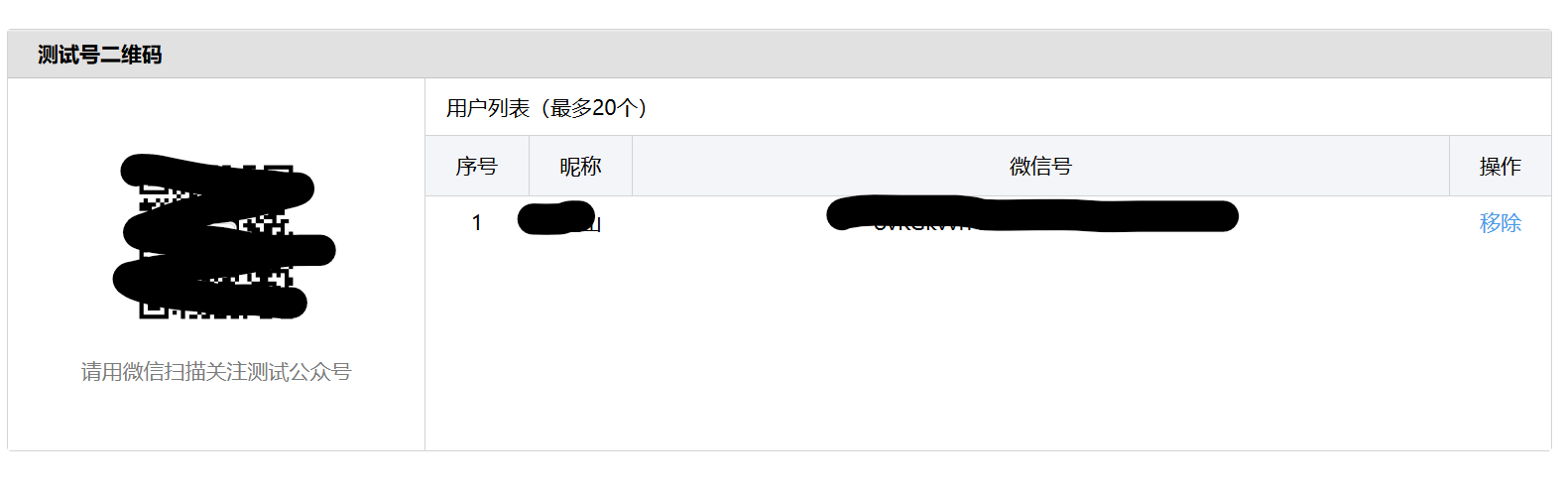
最后,我们需要一个消息模板。在“模板消息接口”部分,点击“新增测试模板”,填写如下信息:
- 模板标题:
审稿状态变更通知(或其他你喜欢的标题) - 模板内容:
提交后,你会获得一个模板ID,例如{{title.DATA}} 检查时间:{{check_time.DATA}} 变更前状态:{{old_status.DATA}} 变更后状态:{{new_status.DATA}}aBcDeFg-hIjKlMn...。记下它: status_template_id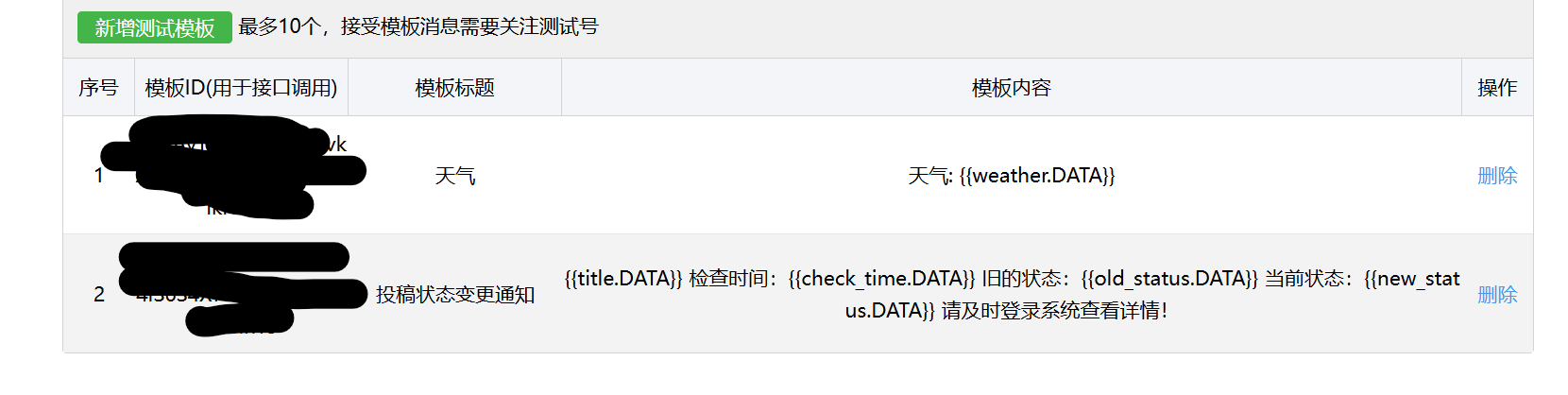
3. 创建配置文件
为了不将密码、密钥等敏感信息直接写在代码里,我们创建一个名为 .env 的文件,将所有配置信息放进去。在你的项目根目录下创建该文件,并填入以下内容:
# 微信测试号信息
APPID=你的appID
APPSECRET=你的appSecret
OPENID=你的用户列表里的微信号
STATUS_TEMPLATE_ID=你刚刚申请的模板ID
# 期刊投稿网站的登录信息
JOURNAL_USERNAME=你的投稿网站用户名
JOURNAL_PASSWORD=你的投稿网站密码
Part 3: 代码详解 - 赋予机器人生命
准备工作就绪,现在让我们进入最激动人心的编码环节。以下是完整的代码,我已经为你添加了详尽的注释,解释了每一部分的作用。
# 模拟真人版
import os
import time
import requests
import random
import datetime
import json
import schedule
from pathlib import Path
from playwright.sync_api import sync_playwright, TimeoutError, Error as PlaywrightError
from dotenv import load_dotenv
# --- 1. 初始化与配置加载 ---
load_dotenv() # 加载 .env 文件中的环境变量
# 从环境变量中读取配置信息
appID = os.getenv("APPID")
appSecret = os.getenv("APPSECRET")
openId = os.getenv("OPENID")
status_template_id = os.getenv("STATUS_TEMPLATE_ID")
journal_username = os.getenv("JOURNAL_USERNAME")
journal_password = os.getenv("JOURNAL_PASSWORD")
# 定义常量
STATUS_FILE = Path("journal_data.json") # 用于存储上次状态和会话信息的文件
MAX_RETRIES = 3 # 最大失败重试次数
# --- 2. 辅助函数 ---
def type_like_human(locator, text_to_type):
"""模拟真人逐字输入,并带有随机间隔,有效防止被网站识别为机器人"""
locator.hover() # 先将鼠标悬停在输入框上
time.sleep(random.uniform(0.5, 1.0)) # 短暂思考
for char in text_to_type:
locator.press(char)
time.sleep(random.uniform(0.08, 0.25)) # 模拟打字速度
def get_saved_data():
"""从本地JSON文件读取上次的状态和Cookies"""
if not STATUS_FILE.exists():
return {"last_status": "首次运行", "storage_state": None}
try:
with open(STATUS_FILE, 'r') as f:
data = json.load(f)
return {
"last_status": data.get("last_status", "首次运行"),
"storage_state": data.get("storage_state")
}
except (json.JSONDecodeError, IOError):
return {"last_status": "文件读取错误", "storage_state": None}
def save_data(status, storage_state):
"""将最新状态和Cookies保存到本地JSON文件"""
with open(STATUS_FILE, 'w') as f:
json.dump({"last_status": status, "storage_state": storage_state}, f, indent=4)
print(f" -> 最新状态 '{status}' 和会话信息已保存至 {STATUS_FILE}")
def get_access_token():
"""获取与微信服务器通信的凭证 (access_token)"""
url = f'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={appID.strip()}&secret={appSecret.strip()}'
try:
response = requests.get(url).json()
access_token = response.get('access_token')
if access_token:
print(" -> 成功获取 access_token。")
return access_token
else:
print(f" -> [错误] 获取 access_token 失败: {response.get('errmsg')}")
return None
except requests.RequestException as e:
print(f" -> [错误] 请求 access_token 时网络异常: {e}")
return None
def send_status_update(access_token, last_status, current_status):
"""调用微信API,发送模板消息通知"""
check_time_str = datetime.datetime.now().strftime("%Y年%m月%d日 %H:%M")
url = f"https://api.weixin.qq.com/cgi-bin/message/template/send?access_token={access_token}"
payload = {
"touser": openId,
"template_id": status_template_id,
"data": {
"title": {"value": "您的期刊投稿状态有新的变化!", "color": "#FF0000"}, # 红色标题
"check_time": {"value": f" {check_time_str}"},
"old_status": {"value": f" {last_status}"},
"new_status": {"value": f" {current_status}"}
}
}
try:
response = requests.post(url, json=payload, timeout=10)
response.raise_for_status() # 如果请求失败 (非2xx状态码),则抛出异常
result = response.json()
if result.get("errcode") == 0:
print(" -> 微信通知发送成功!")
else:
print(f" -> [错误] 微信通知发送失败: {result.get('errmsg')}")
except requests.RequestException as e:
print(f" -> [错误] 发送微信通知时发生网络异常: {e}")
# --- 3. 核心任务函数 ---
def check_journal_status():
"""期刊状态检查任务的完整流程"""
initial_delay = random.randint(1, 60)
print(f"\n【{time.strftime('%Y-%m-%d %H:%M:%S')}】 任务触发,为模拟人类操作,随机延迟 {initial_delay} 秒...")
time.sleep(initial_delay)
print(f"--- 开始执行期刊状态检查 ---")
current_status = ""
saved_data = get_saved_data()
for attempt in range(MAX_RETRIES):
try:
with sync_playwright() as p:
# 启动一个“干净”的浏览器,伪装成普通用户
browser = p.chromium.launch(
headless=True, # 无头模式,在后台运行,不弹出浏览器窗口
args=["--start-maximized", "--disable-blink-features=AutomationControlled"]
)
# 创建一个浏览器上下文,加载上次保存的登录信息 (storage_state)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
storage_state=saved_data.get('storage_state'),
no_viewport=True,
)
page = context.new_page()
print(" -> 正在导航至期刊登录入口...")
page.goto("https://www.editorialmanager.com/bae/default2.aspx", wait_until="domcontentloaded")
main_frame = page.frame_locator('iframe[name="content"]')
# 【核心登录逻辑】尝试直接访问,如果失败 (说明Session过期),则执行登录
try:
# 检查页面是否已经包含 "Current Status" 这个标志性文本,来判断是否已登录
main_frame.get_by_text("Current Status", exact=True).wait_for(state="visible", timeout=10000)
print(" -> 检测到有效会话,已自动登录。")
except TimeoutError:
print(" -> 会话已过期或未登录,执行登录流程。")
login_frame = main_frame.frame_locator('iframe[name="login"]')
type_like_human(login_frame.locator("#username"), journal_username)
type_like_human(login_frame.locator("#passwordTextbox"), journal_password)
login_button = login_frame.locator('#emLoginButtonsDiv > input[type=button]:nth-child(1)')
login_button.click()
# 等待登录成功后的页面标志出现,而不是盲等时间
print(" -> 登录按钮已点击,等待页面跳转...")
# 点击“Submissions Being Processed”链接,进入稿件列表
main_frame.get_by_text("Submissions Being Processed").click()
page.wait_for_load_state("load", timeout=30000)
print(" -> 登录成功,页面已加载。")
# --- 抓取状态 ---
print(" -> 正在抓取稿件状态...")
try:
# 定位到稿件列表的第一行
first_row = main_frame.locator("table#datatable tr#row1")
first_row.wait_for(state="visible", timeout=20000)
# 定位到状态所在的单元格 (第6列,索引为5)
status_cell = first_row.locator("td").nth(5)
current_status = status_cell.text_content().strip()
print(f" -> 成功抓取到当前状态:'{current_status}'")
except TimeoutError:
current_status = "无在处理的投稿" # 如果找不到表格,说明没有稿件
print(" -> 未发现正在处理的投稿。")
except Exception as e:
current_status = "抓取页面元素时出错"
print(f" -> [错误] 定位状态元素时失败: {e}")
# 【关键一步】保存本次会话的最新Cookies等信息
latest_storage_state = context.storage_state()
browser.close()
# --- 比较状态并决定是否通知 ---
last_status = saved_data['last_status']
print(f" -> 上次记录的状态是:'{last_status}'")
if current_status and current_status != last_status:
print(f" -> !!! 状态发生变化 ({last_status} -> {current_status}),准备发送微信通知 !!!")
access_token = get_access_token()
if access_token:
send_status_update(access_token, last_status, current_status)
# 只有在通知成功后,才更新本地记录的状态
save_data(current_status, latest_storage_state)
else:
print(" -> 获取access_token失败,本次状态将不会被保存,等待下次重试。")
else:
print(" -> 状态无变化,无需通知。")
# 状态没变,但也要更新会话信息,保持登录状态活跃
save_data(last_status, latest_storage_state)
print("--- 本次期刊状态检查任务完成 ---\n")
return # 成功完成任务,跳出重试循环
except (PlaywrightError, TimeoutError) as e:
print(f" -> [严重错误] 第 {attempt + 1}/{MAX_RETRIES} 次尝试失败: {type(e).__name__}")
if attempt < MAX_RETRIES - 1:
sleep_time = (attempt + 1) * 60 # 失败后,等待更长时间再重试
print(f" -> 将在 {sleep_time} 秒后重试...")
time.sleep(sleep_time)
else:
print(" -> 已达到最大重试次数,任务中断。等待下一个调度周期。")
return # 放弃本次任务
# --- 4. 启动与调度 ---
if __name__ == '__main__':
print("自动化监控脚本启动成功!")
# 立即执行一次,以便快速验证配置是否正确
check_journal_status()
# 设置定时任务:每隔45分钟执行一次检查
print(f"任务 'check_journal_status' 已被调度,将每45分钟执行一次。")
schedule.every(45).minutes.do(check_journal_status)
last_heartbeat_time = time.time()
# 启动一个无限循环来运行调度器
while True:
schedule.run_pending()
# 为了方便监控脚本是否存活,每10分钟打印一条“心跳”日志
current_time = time.time()
if current_time - last_heartbeat_time > 600:
print(f"[{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] 服务心跳:正常运行中,安静等待下一个任务...")
last_heartbeat_time = current_time
time.sleep(1)
Part 4: 运行与部署,使用 systemd 实现应用的专业级后台运行
在上一部分,我们成功在本地运行了脚本。但要让我们的监控机器人成为一个7x24小时的服务,就需要将它部署到一台云服务器上,并确保它能稳定地在后台运行,甚至在服务器重启后也能自动“复活”。
虽然 nohup python your_script_name.py & 是一个快速启动后台任务的方法,但它就像用胶带固定东西——临时有效,却不够专业。当我们需要自动重启、统一日志管理和开机自启时,systemd 才是Linux世界的“瑞士军刀”。
为什么选择 systemd?
- 守护神模式:
systemd会像守护神一样照看你的程序。如果脚本意外崩溃(例如,网络抖动导致Playwright超时),systemd可以自动尝试重启它。 - 开机自启: 设置一次,高枕无忧。服务器因维护重启后,
systemd会自动运行你的脚本,无需手动干预。 - 标准化管理: 使用统一、简洁的命令 (
systemctl start,stop,status) 来管理你的应用,非常清晰。 - 集中式日志: 告别散乱的
nohup.out文件。systemd将所有输出(包括错误信息)都交由journald管理,你可以用journalctl命令轻松查看、过滤和跟踪日志。
部署步骤
前提条件:
- 你已经有一台Linux云服务器(例如 Ubuntu 20.04 或更高版本)。
- 你已经将项目文件(
.py脚本和.env文件)上传到了服务器的某个目录,例如:/home/youruser/journal_monitor。 - 你已经在服务器上配置好了Python环境,并安装了所有依赖(
pip install -r requirements.txt),最重要的是,已成功运行过playwright install。
第1步:创建systemd服务文件
systemd 通过 .service 配置文件来管理服务。我们需要在 /etc/systemd/system/ 目录下为我们的应用创建一个这样的文件。
使用你喜欢的文本编辑器(这里用 nano 举例)来创建它。因为是系统目录,所以需要 sudo 权限。
sudo nano /etc/systemd/system/journal-monitor.service
第2步:编写服务文件内容
将以下内容复制并粘贴到你打开的 nano 编辑器中。请务必根据你的实际情况修改 [Service] 部分的路径和用户名。
[Unit]
Description=Journal Status Monitor Service
# 这个设置确保服务在网络连接就绪后才启动,对我们的脚本至关重要
After=network.target
[Service]
# 【请修改】运行此脚本的用户名
User=youruser
# 【请修改】运行此脚本的用户组
Group=yourgroup
# 【请修改】你的项目所在的根目录
WorkingDirectory=/home/youruser/journal_monitor
# 【请修改】启动脚本的命令。这里是关键!
# 1. 使用 `which python3` 找到你环境中python解释器的绝对路径。
# 2. 后面跟上你的python脚本的绝对路径。
ExecStart=/home/youruser/my_python_env/bin/python3 /home/youruser/journal_monitor/your_script_name.py
# Playwright在非交互式环境中可能需要这个环境变量来找到浏览器
# 如果Playwright找不到浏览器,请取消下面这行的注释并指向正确路径
# Environment="PLAYWRIGHT_BROWSERS_PATH=/home/youruser/.cache/ms-playwright"
# 核心功能:当服务因非正常退出(即发生错误)时,自动重启
Restart=on-failure
# 两次重启之间的间隔时间(秒)
RestartSec=30
[Install]
# 这使得服务可以在系统启动时自动运行
WantedBy=multi-user.target
配置说明:
Description: 一个易于理解的服务描述。User/Group: 指定用哪个用户身份运行脚本。强烈建议使用一个非root的普通用户,这更安全。通常用户名和用户组名是相同的。WorkingDirectory: 脚本的“工作主场”。这非常重要,因为我们的代码依赖于相对路径的.env文件和journal_data.json文件。ExecStart: 这是最核心的配置。它告诉systemd如何启动你的程序。必须使用绝对路径!- 如何找到Python解释器的绝对路径? 如果你使用了虚拟环境(强烈推荐),先激活环境 (
source my_python_env/bin/activate),然后运行which python3。它会输出类似/home/youruser/my_python_env/bin/python3的路径。
- 如何找到Python解释器的绝对路径? 如果你使用了虚拟环境(强烈推荐),先激活环境 (
Restart=on-failure: 我们的“守护神”条款,确保了服务的健壮性。WantedBy=multi-user.target: 这是实现开机自启的钩子。
写好之后,按 Ctrl+X,然后按 Y,最后按 Enter 保存并退出 nano。
第3步:管理你的新服务
现在,我们可以用 systemctl 命令来指挥我们的服务了。
重新加载
systemd配置 每次创建或修改.service文件后,都需要运行此命令来让systemd识别到变更。sudo systemctl daemon-reload启动服务
sudo systemctl start journal-monitor.service运行后,你的脚本就已经在后台悄悄地工作了。
检查服务状态 (非常重要!) 这是你调试和确认服务是否正常运行的首选命令。
sudo systemctl status journal-monitor.service如果一切顺利,你会看到绿色的
active (running)字样,下面还会显示最近几条日志输出。如果服务启动失败,这里会显示红色的failed以及错误信息,为你提供调试线索。设置开机自启 让服务在服务器重启后自动运行。
sudo systemctl enable journal-monitor.service ```你会看到一条消息,提示创建了一个符号链接,这表示设置成功。停止与重启服务 当你需要更新代码时,可以先停止服务,更新文件后,再重启服务。
# 停止服务 sudo systemctl stop journal-monitor.service # 重启服务 (相当于 stop + start) sudo systemctl restart journal-monitor.service
查看和跟踪日志
现在,所有的 print 输出都会被 journalctl 捕获。
查看服务的所有日志:
sudo journalctl -u journal-monitor.service实时跟踪日志 (像
tail -f): 这个命令非常有用,可以实时看到脚本正在打印什么内容。sudo journalctl -u journal-monitor.service -f查看最近100行日志:
sudo journalctl -u journal-monitor.service -n 100
至此,你已经成功地将你的Python应用部署成了一个专业、稳定、可管理的系统服务。现在,你可以安心地关闭SSH连接,你的监控机器人会忠实地在云端为你站岗放哨。
总结
通过这个项目,我们不仅解决了一个实际的痛点,还实践了一套非常现代化的Web自动化和API集成的技术。这个脚本的核心逻辑——“登录 - 抓取 - 储存 - 对比 - 通知”——是一个万能模板,稍加改造,就可以应用于各种场景。技术的魅力就在于此——将重复、繁琐的劳动自动化,让我们能更专注于创造性的工作。希望这篇教程能为你打开一扇新的大门,快去动手试试吧!


评论区