



前言
在数据驱动的今天,网络上蕴藏着海量有价值的信息。作为中国领先的在线旅游平台,携程的游记频道包含了大量关于旅行目的地、行程规划、人均花费的真实数据。如果我们能将这些数据结构化地抓取下来,就可以进行有趣的数据分析,比如分析某个城市最受欢迎的景点、不同季节的旅行成本变化等等。
本文旨在提供一个清晰、完整且高度可复用的爬虫解决方案。我们将以爬取“景德镇”的旅行游记为例,最终实现一个可以轻松扩展到任何城市的自动化数据采集器。
核心技术栈
- HTTP请求:
requests - HTML解析:
lxml - 并发处理:
multiprocessing.dummy(线程池) - 反爬策略:
fake_useragent(随机User-Agent) - 数据存储:
openpyxl(操作Excel) - 代码结构: 面向对象编程 (OOP)
爬虫设计思路:三步走的策略
一个稳健的爬虫项目,通常可以分为三个核心部分:数据获取、数据解析和数据存储。我们的代码也将围绕这三个步骤展开,并将它们封装在一个 CtripTravelScraper 类中,以实现高度模块化。
- 数据获取 (
_make_request): 负责与网站服务器打交道。它需要足够“聪明”和“礼貌”,能够模拟浏览器行为,处理网络异常,并在失败时自动重试。 - 数据解析 (
_parse_list_page,_parse_detail_page): 获取到HTML源码后,我们需要像侦探一样,从中筛选并提取出我们关心的信息,如标题、作者、花费、游玩地点等。 - 数据存储 (
save_data_to_excel): 将解析出的非结构化数据,整理成规范的格式,并永久保存在Excel文件中,方便后续使用。
代码详解
第一步:封装一个强大的请求模块
网络请求是爬虫的生命线。为了应对携程可能的反爬策略和网络波动,我们的 _make_request 方法做了三件事:
- 随机User-Agent: 通过
fake_useragent库,我们的爬虫在每次请求时都会伪装成一个不同的、真实的浏览器,大大降低了被识别为机器人的风险。 - 设置Referer: 模拟用户是从携程主站点击进入游记列表的,增加了请求的“可信度”。
- 异常处理与重试: 使用
try...except块捕获所有可能的RequestException,并在请求失败时,自动进行多次重试,保证了爬虫的稳定性。
# headers中的关键设置
headers = {
'cookie': '', # 【关键】请务必填入您自己的有效cookie
'referer': 'https://you.ctrip.com',
'User-Agent': UserAgent().random # 每次请求都使用随机UA
}
# ...
# 重试逻辑
for i in range(attempt_limit):
try:
response = requests.get(url, headers=headers, timeout=self.request_timeout)
response.raise_for_status() # 状态码非200则抛出异常
return response.text
except RequestException as e:
print(f"URL: {url} 请求失败 (第 {i+1} 次尝试): {e}")
if i < attempt_limit - 1:
time.sleep(5) # 等待5秒后重试
注意:cookie 是应对当前网站反爬最关键的环节。请务必在浏览器中登录你的携程账号,并通过开发者工具(F12)获取你的cookie,并粘贴到代码中。
第二步:精准解析,提取数据
携程的游记数据分散在列表页和详情页。我们采用“先抓列表,再补全详情”的策略。
解析列表页 (_parse_list_page):
我们使用 lxml 的 xpath 语法来定位页面元素。XPath就像是HTML的“寻宝图”,可以让我们精确地找到每一个标题、链接和作者信息。我们发现,大部分关键信息(天数、花费、日期)都集中在一个元数据块中,因此我们先将整个块的文本提取出来,再用正则表达式 (re.search) 分别匹配,这种方法比依赖固定的HTML结构更稳健。
解析详情页 (_parse_detail_page):
在获取到每篇游记的独立链接后,我们再次发起请求,进入详情页。在这里,我们主要抓取游记正文摘要和其中提到的游玩地点 (POI)。
# 示例:使用XPath定位所有游记项目
articles = tree.xpath('//a[@class="journal-item cf"]')
# 示例:使用正则表达式从文本块中提取花费
cost = re.search(r'¥(\d+)/人', meta_text)
avg_cost_person = cost.group(1) if cost else 'N/A'
第三步:多线程加速与数据持久化
顺序地一页一页爬取、一篇一篇处理,效率会非常低下。这里我们引入了multiprocessing.dummy库,它提供了一个与多进程库接口完全相同的线程池。
并发执行 (run方法):
我们创建一个线程池,并将所有需要爬取的页码(例如2到100页)作为一个任务列表,交给线程池的 pool.map() 方法。map 方法会自动为每个页码分配一个线程去执行我们的 scrape_single_page 函数。这样一来,原本需要数小时的任务,可能几分钟就能完成。
with Pool(self.thread_pool_size) as pool:
# map会自动处理任务分发和结果回收
results_from_all_pages = pool.map(self.scrape_single_page, page_numbers_to_scrape)
# 将所有线程返回的结果合并
for page_result in results_from_all_pages:
self.scraped_data.extend(page_result)
保存到Excel (save_data_to_excel):
爬取到的数据最终需要一个好的归宿。我们使用 openpyxl 库来创建一个Excel工作簿。代码会自动创建表头,遍历我们收集到的所有数据,并逐行写入。最后,我们还贴心地加入了一个自动调整列宽的功能,让最终生成的表格既美观又易于阅读。
如何使用这个爬虫?
我们的代码被设计为“开箱即用”,只需简单四步即可爬取任意城市的数据。
步骤1:安装依赖库
首先,确保你的Python环境中安装了所有必需的库。
pip install requests lxml openpyxl fake-useragent
步骤2:获取你的个人Cookie
这是应对简单反爬虫机制关键的一步。
- 在Chrome或Edge浏览器中,访问并登录
https://you.ctrip.com。 - 按
F12键打开“开发者工具”。 - 切换到“网络 (Network)”标签页。
- 刷新一下页面,在请求列表中随便点击一个,然后在右侧找到“请求标头 (Request Headers)”,向下滚动找到
cookie字段,并复制它完整的长字符串值。
步骤3:确定目标城市的参数 (city_pinyin 和 city_code)
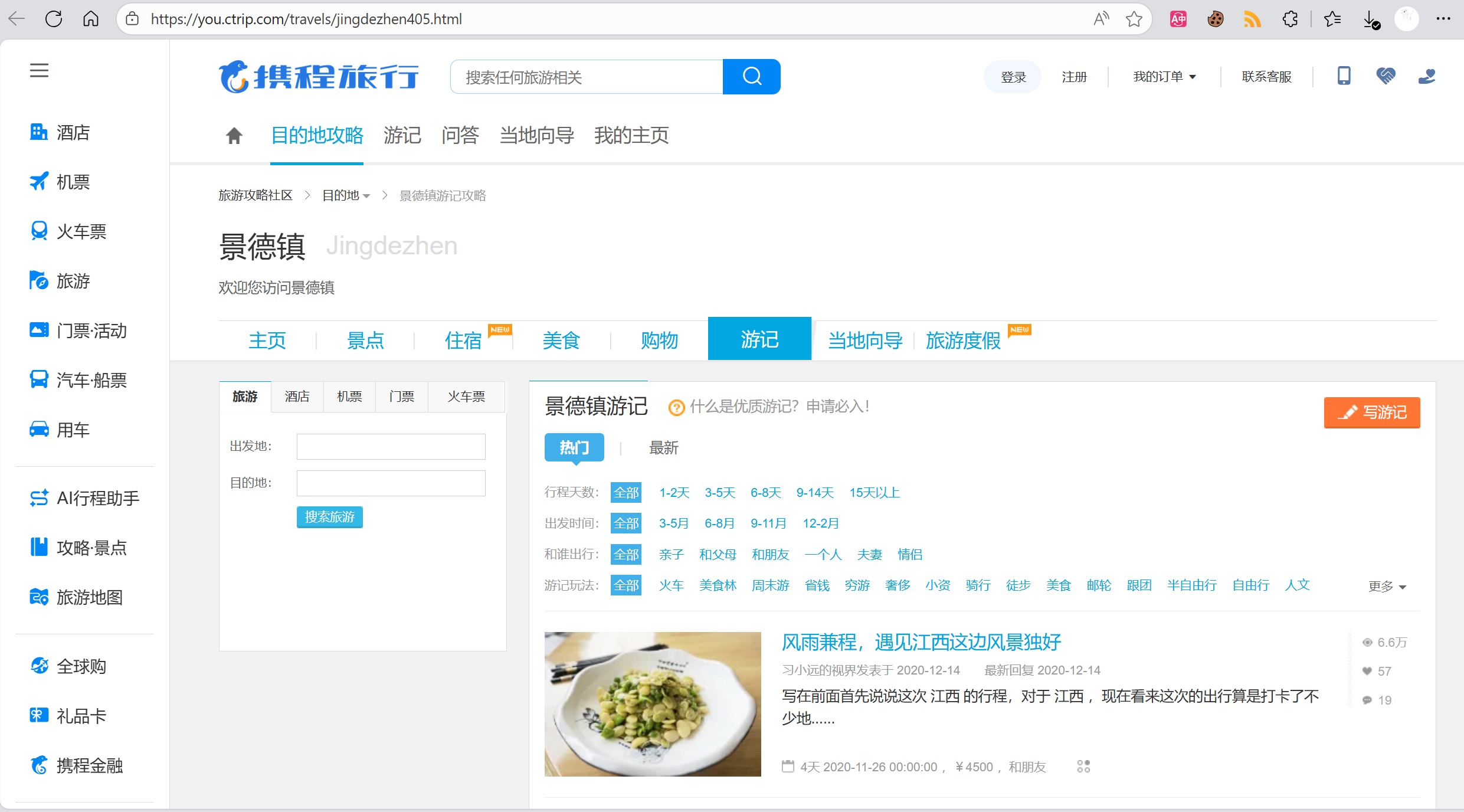
要爬取不同的城市,你需要找到它在携程网址中的专属代号。
- 打开携程旅行网:
https://you.ctrip.com。 - 在顶部的搜索框中,输入您想爬取的城市,例如 “北京”,然后搜索。
- 点击进入北京的游记列表页。
- 关键一步:观察浏览器地址栏的URL。 您会看到类似这样的地址:
https://you.ctrip.com/travels/beijing1/ - 从URL中提取参数:
- 在
beijing1中,beijing就是city_pinyin,1就是city_code。 - 同理,如果您搜索“成都”,它的URL是
.../travels/chengdu104/,那么city_pinyin就是chengdu,city_code就是104。
- 在
步骤4:配置并运行脚本
现在,你可以配置并运行下面提供的完整代码了。
- 修改Cookie: 将步骤2中复制的Cookie字符串,粘贴到
_make_request方法内headers字典的cookie字段中。 - 修改城市和页码: 在代码最下方的
if __name__ == "__main__":部分,根据步骤3找到的参数,修改city_pinyin和city_code。同时,你也可以自由设置start_page(起始页) 和end_page(结束页)。
例如,要爬取北京的第1到5页游记:
# 找到代码最后的部分,进行如下修改
scraper = CtripTravelScraper(
city_pinyin='beijing',
city_code=1,
start_page=1,
end_page=5
)
scraper.run()
运行脚本:
python your_script_name.py稍等片刻,一个名为
携程旅行见闻.xlsx的文件就会出现在你的项目目录中,里面包含了所有抓取到的数据!
总结
至此,我们不仅构建了一个功能强大的携程游记爬虫,更重要的是,我们学习了一套完整的爬虫项目设计思想:从面向对象的结构设计,到多线程的效率优化,再到反爬策略和数据存储的实践。希望这篇文章能为你打开数据抓取世界的大门,并为你未来的学习提供有价值的参考。
如果你有任何问题或改进建议,欢迎在评论区留言交流!
完整代码
下面是可以直接复制并运行的完整Python脚本。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
携程旅行见闻自动化采集器
通过面向对象与多线程技术,实现对指定目的地旅行见闻的高效抓取与数据持久化。
"""
import time
import requests
import openpyxl
import re
from lxml import etree
from multiprocessing.dummy import Pool
from requests.exceptions import RequestException
from fake_useragent import UserAgent
class CtripTravelScraper:
"""
一个用于爬取携程游记数据的类。
通过初始化配置,可以启动一个多线程爬虫任务,并将结果保存到Excel。
"""
def __init__(self, city_pinyin, city_code, start_page=1, end_page=2, pool_size=3, retries=3, output_filename='携程旅行见闻.xlsx'):
"""
初始化爬虫配置
:param city_pinyin: 城市拼音 (例如: 'jingdezhen')
:param city_code: 城市代码 (例如: 405)
:param start_page: 起始页码
:param end_page: 结束页码
:param pool_size: 线程池大小
:param retries: 请求失败重试次数
:param output_filename: 输出文件名
"""
self.base_url_template = f'https://you.ctrip.com/travels/{city_pinyin}{city_code}/t3-p{{}}.html'
self.start_page = start_page
self.end_page = end_page
self.thread_pool_size = pool_size
self.retry_attempts = retries
self.request_timeout = 20
self.output_file = output_filename
self.scraped_data = [] # 用于线程安全地收集数据
def _make_request(self, url, attempt_limit=None):
"""
执行HTTP GET请求,内置重试和随机User-Agent机制。
"""
if attempt_limit is None:
attempt_limit = self.retry_attempts
headers = {
'cookie': '', # 【关键】请务必填入您自己的有效cookie
'referer': 'https://you.ctrip.com',
'User-Agent': UserAgent().random # 每次请求都使用随机UA
}
for i in range(attempt_limit):
try:
response = requests.get(url, headers=headers, timeout=self.request_timeout)
response.raise_for_status() # 如果状态码不是200, 则引发HTTPError
return response.text
except RequestException as e:
print(f"URL: {url} 请求失败 (第 {i+1} 次尝试): {e}")
if i < attempt_limit - 1:
time.sleep(5) # 等待5秒后重试
return None
def _parse_detail_page(self, article_url, base_info):
"""
解析游记的详情页面,提取正文内容、游玩地点等补充信息。
"""
html_content = self._make_request(article_url)
if not html_content:
return base_info
try:
tree = etree.HTML(html_content)
# 提取正文摘要
content_nodes = tree.xpath('//div[@class="ctd_content"]//text()')
full_content = ' '.join(text.strip() for text in content_nodes if text.strip())
# 提取游玩过的地点
poi_nodes = tree.xpath('//div[@class="ctd_content"]//a[contains(@class, "poi")]/text()')
places_visited = '、'.join(place.strip() for place in poi_nodes if place.strip())
# 更新基础信息字典
base_info.update({
'places_visited': places_visited,
'content_summary': full_content[:500].strip() + '...' if len(full_content) > 500 else full_content.strip()
})
except Exception as e:
print(f"解析详情页 {article_url} 出错: {e}")
return base_info
def _parse_list_page(self, html_content):
"""
从列表页HTML中解析出各个游记的基础信息。
"""
tree = etree.HTML(html_content)
articles = tree.xpath('//a[@class="journal-item cf"]')
parsed_articles = []
for article_node in articles:
try:
title = article_node.xpath('.//dt[@class="ellipsis"]/text()')[0].strip()
article_link = 'https://you.ctrip.com' + article_node.xpath('./@href')[0]
# 解析元数据块
meta_elements = article_node.xpath('.//dd[@class="item-extra"]/*')
meta_text = ' '.join(el.text.strip() for el in meta_elements if el.text)
days = re.search(r'(\d+)天', meta_text)
travel_date = re.search(r'(\d{4}-\d{2}-\d{2})', meta_text)
cost = re.search(r'¥(\d+)/人', meta_text)
# 解析作者信息
author_text = article_node.xpath('.//dd[@class="item-user"]/text()')[0].strip()
author_match = re.search(r'(.+?)发表于', author_text)
author = author_match.group(1).strip() if author_match else author_text
article_data = {
'title': title,
'url': article_link,
'days_span': days.group(0) if days else 'N/A',
'publish_date': travel_date.group(0) if travel_date else 'N/A',
'avg_cost_person': cost.group(1) if cost else 'N/A',
'author': author
}
parsed_articles.append(article_data)
except Exception as e:
print(f"解析列表中的某个项目时出错: {e}")
return parsed_articles
def scrape_single_page(self, page_number):
"""
负责抓取并处理单个页码的所有游记。
"""
page_url = self.base_url_template.format(page_number)
print(f"开始抓取第 {page_number} 页: {page_url}")
list_html = self._make_request(page_url)
if not list_html:
print(f"未能获取第 {page_number} 页的内容,跳过。")
return []
articles_on_page = self._parse_list_page(list_html)
print(f"第 {page_number} 页发现 {len(articles_on_page)} 篇游记。")
page_results = []
for article_base_info in articles_on_page:
print(f" -> 正在处理详情页: {article_base_info['title']}")
detailed_info = self._parse_detail_page(article_base_info['url'], article_base_info)
page_results.append(detailed_info)
time.sleep(1.5) # 友好爬取,增加请求间隔
return page_results
def save_data_to_excel(self):
"""
将收集到的所有数据写入Excel文件。
"""
if not self.scraped_data:
print("警告:没有收集到任何数据,无法生成Excel文件。")
return
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = "携程游记数据"
# 定义并写入表头
headers = [
'标题', '链接', '旅行天数', '发布日期', '人均花费(元)',
'作者', '游玩地点', '内容摘要'
]
sheet.append(headers)
# 写入数据行
for item in self.scraped_data:
row_data = [
item.get('title', ''),
item.get('url', ''),
item.get('days_span', ''),
item.get('publish_date', ''),
item.get('avg_cost_person', ''),
item.get('author', ''),
item.get('places_visited', ''),
item.get('content_summary', '')
]
sheet.append(row_data)
# 自动调整列宽
for column_cells in sheet.columns:
max_len = 0
column = column_cells[0].column_letter
for cell in column_cells:
try:
cell_len = len(str(cell.value))
if cell_len > max_len:
max_len = cell_len
except:
pass
adjusted_width = (max_len + 2) if max_len < 50 else 50
sheet.column_dimensions[column].width = adjusted_width
workbook.save(self.output_file)
print(f"任务完成!数据已成功保存至: {self.output_file}")
def run(self):
"""
启动爬虫主程序。
"""
start_time = time.time()
print("="*50)
print("携程旅行见闻采集器已启动")
print(f"目标页码范围: 从 {self.start_page} 到 {self.end_page}")
print(f"线程数: {self.thread_pool_size}")
print("="*50)
page_numbers_to_scrape = range(self.start_page, self.end_page + 1)
with Pool(self.thread_pool_size) as pool:
# map会阻塞,直到所有任务完成
results_from_all_pages = pool.map(self.scrape_single_page, page_numbers_to_scrape)
# 将嵌套列表展开
for page_result in results_from_all_pages:
self.scraped_data.extend(page_result)
print(f"\n所有页面处理完毕,共收集到 {len(self.scraped_data)} 条数据。")
self.save_data_to_excel()
end_time = time.time()
print(f"总耗时: {end_time - start_time:.2f} 秒。")
if __name__ == "__main__":
# ========== 爬虫实例化与启动 ==========
# 配置目标城市 (景德镇) 和爬取范围
scraper = CtripTravelScraper(
city_pinyin='jingdezhen',
city_code=405,
start_page=2,
end_page=3
)
scraper.run()


评论区